5.1. 地理空間篩選
![]()
Table Of Contents
民生公共物聯網的測站都有其空間位置,由於同一區域內常有類似的環境因子,所以它們的感測數值也會具有類似的起伏趨勢,而這也就是地理學的第一定律:“All things are related, but nearby things are more related than distant things.” (Waldo R. Tobler)
此外,單一測站的感測數據有可能因為局部干擾因子的影響,而產生較大的起伏,所以為進一步確認數據的可信度,我們會需要以單一測站為中心,依照其所屬的行政區或是指定距離 (半徑),選取鄰近的測站ID與數值,並將其以表單或地圖的方式呈現,以便進行比對。
這個章節中,我們會利用環保署的空品測站、氣象局的局屬測站以及水利署在各縣市佈建的淹水感測器,示範如何利用地理空間篩選測站,並以其「位置」與「數值」為基礎,轉化成可利用的空間資訊。
# 引入 matplotlib、seaborn 等繪圖模組
import matplotlib.pyplot as plt
import seaborn as sns
# 引入 pandas 和 numpy 進行數據分析
import pandas as pd
import numpy as np
# 引入 urllib.request 來處理網路資源
import urllib.request
# 引入 ssl 和 json 來處理安全連線和 JSON 格式
import ssl
import json
# 安裝 geopython 相關套件,主要是用在地理資料處理
!apt install gdal-bin python-gdal python3-gdal
# 安裝 python3-rtree,這是 Geopandas 的需求
!apt install python3-rtree
# 安裝 Geopandas,用於處理地理資料
!pip install geopandas
# 安裝 descartes,也是 Geopandas 的需求
!pip install descartes
# 引入 geopandas 模組
import geopandas as gpd
# 安裝 pyCIOT 模組,這是專門用於 CIoT 數據處理的
!pip install pyCIOT
# 引入 pyCIOT 的數據處理模組
import pyCIOT.data as CIoT
# 前往政府開放資料庫下載 縣市界線(TWD97經緯度) 的資料,並解壓縮到名為 shp 的資料夾
# 使用 wget 指令下載一個名為 "shp.zip" 的壓縮檔,檔案來源網址是內政部開放資料平台
!wget -O "shp.zip" -q "https://data.moi.gov.tw/MoiOD/System/DownloadFile.aspx?DATA=72874C55-884D-4CEA-B7D6-F60B0BE85AB0"
# 使用 unzip 指令解壓縮 "shp.zip",並將解壓縮的內容存到 "shp" 資料夾
!unzip shp.zip -d shp
# 從 pyCIOT 取得水利署淹水感測器資料和天氣資料
wa = CIoT.Water().get_data(src="FLOODING:WRA")
wa2 = CIoT.Water().get_data(src="FLOODING:WRA2")
wea_list = CIoT.Weather().get_station('GENERAL:CWB')
# 讀取台灣縣市邊界的 shapefile
county = gpd.read_file('county.shp')
# 篩選出嘉義縣和嘉義市的資料作為底圖
basemap = county.loc[county['COUNTYNAME'].isin(["嘉義縣","嘉義市"])]
# 合併淹水感測器的資料並轉成 DataFrame 格式
flood_list = wa + wa2
flood_df = pd.DataFrame([],columns = ['name', 'Observations','lon', 'lat'])
# 迴圈處理每個感測器的資料
for i in flood_list:
if len(i['data'])>0:
df = pd.DataFrame([[i['properties']['stationName'],i['data'][0]['values'][0]['value'],i['location']['longitude'],i['location']['latitude']]],columns = ['name', 'Observations','lon', 'lat'])
else:
df = pd.DataFrame([[i['properties']['stationName'],-999,-999,-999]],columns = ['name', 'Observations','lon', 'lat'])
flood_df = pd.concat([flood_df,df])
# 去除重複站點並排序
result_df = flood_df.drop_duplicates(subset=['name'], keep='first')
station=result_df.sort_values(by=['lon', 'lat'])
station = station[station.lon!=-999]
station.reset_index(inplace=True, drop=True)
# 轉成 GeoDataFrame 格式,方便地理資訊處理
gdf_flood = gpd.GeoDataFrame(
station, geometry=gpd.points_from_xy(station.lon, station.lat),crs="EPSG:4326")
# 同樣地,整理天氣資料
weather_df = pd.DataFrame([],columns = ['name','lon', 'lat'])
for i in wea_list:
df = pd.DataFrame([[i['name'],i['location']['longitude'],i['location']['latitude']]],columns = ['name','lon', 'lat'])
weather_df = pd.concat([weather_df,df])
# 去除重複站點並排序,然後轉成 GeoDataFrame
result_df = weather_df.drop_duplicates(subset=['name'], keep='first')
station=result_df.sort_values(by=['lon', 'lat'])
station.reset_index(inplace=True, drop=True)
gdf_weather = gpd.GeoDataFrame(
station, geometry=gpd.points_from_xy(station.lon, station.lat),crs="EPSG:4326")
交集 (Intersect)
一般而言,手邊有很多的測站點位時,我們可以利用村里或鄉鎮等行政區界為範圍,利用資料的在空間上的交集 (intersect) 以篩選出特定行政區內的測站ID,並以API擷取這些測站的:瞬時值、小時平均值、日平均值、週平均值,這樣我們就可以檢視同一行政區內的測站,是否有類似的數值趨勢,抑或哪些測站的數值與其他測站有明顯的差異。
# 引入 matplotlib 和 seaborn 用於繪圖
import matplotlib.pyplot as plt
import seaborn as sns
# 設置畫布和子圖大小
fig, ax = plt.subplots(figsize=(6, 10))
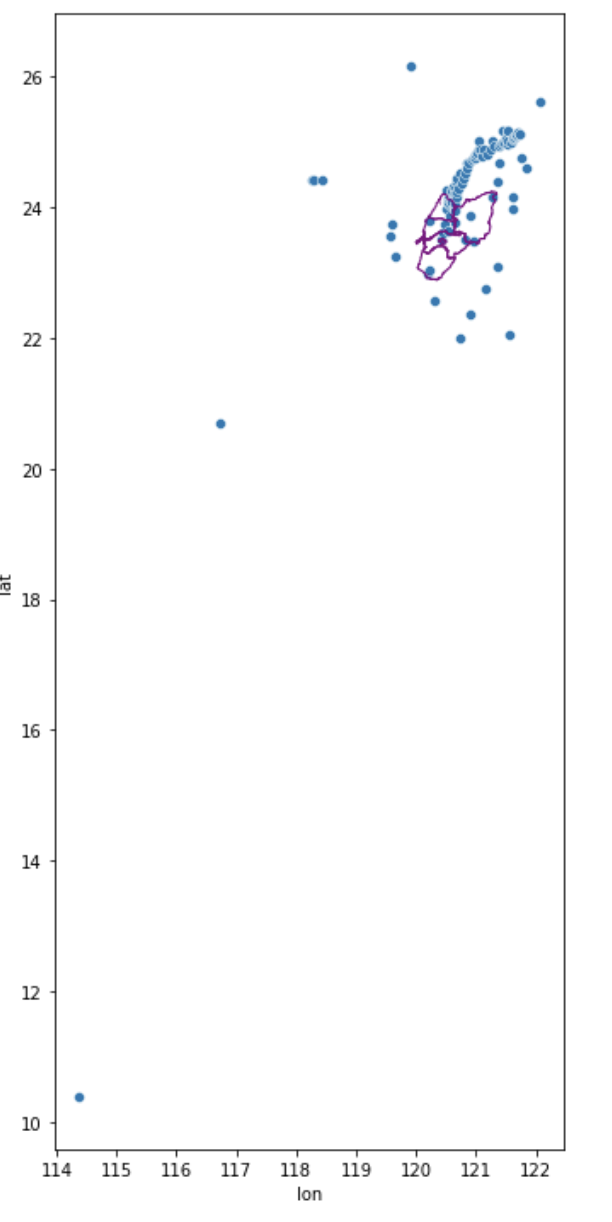
# 使用 seaborn 的 scatterplot 功能,繪製氣象站的經緯度
ax = sns.scatterplot(x='lon', y='lat', data=gdf_weather)
# 使用 Geopandas 的 plot 功能,繪製嘉義縣和嘉義市的邊界
basemap.plot(ax=ax, facecolor='none', edgecolor='purple');
# 調整畫布的排版
plt.tight_layout();
# 將 basemap 的坐標系統設為 EPSG:4326,這樣才能和 gdf_weather 進行操作
basemap = basemap.set_crs(4326, allow_override=True)
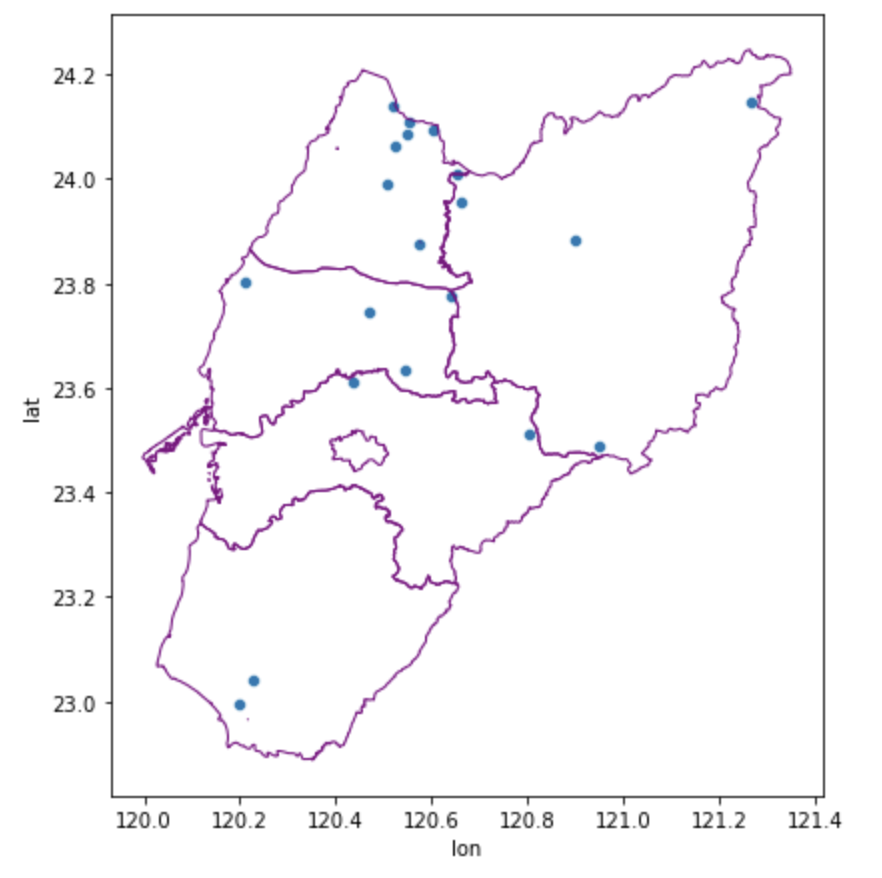
# 使用 Geopandas 的 overlay 函式來找出和嘉義縣、嘉義市邊界重疊的氣象站
intersected_data = gpd.overlay(gdf_weather, basemap, how='intersection')
# 設置畫布和子圖大小
fig, ax = plt.subplots(figsize=(6, 10))
# 繪製過濾後,只在嘉義縣和嘉義市內的氣象站位置
ax = sns.scatterplot(x='lon', y='lat', data=intersected_data)
# 繪製嘉義縣和嘉義市的邊界
basemap.plot(ax=ax, facecolor='none', edgecolor='purple');
# 調整畫布的排版
plt.tight_layout();
緩衝區 (Buffer)
此外,部分測站也有可能是位在兩個行政界的邊界處,所以用行政界當成選取的標準,就有可能出現偏誤。所以這種狀況下,我們可以利用緩衝區 (buffer) 的概念,以測站的座標位置為中心,並指定一個距離半徑以建立一個虛擬的圓形 (圖1),並以此範圍去查找有幾何相交的測站位置。
當我們掌握了緩衝區的概念後,我們也可以某個地標 (例如:學校、公園、工廠…)標為中心,去查找鄰近的測站。甚至,我們可以用一個線段 (Line 例如:道路、河流…) 或一個區域 (polygon 例如:公園、工業區),去建立一個查找範圍,以更具體地找出自己想要的測站點位。在這個範例中,我們以氣象局的局屬氣象站為中心,去建立緩衝區。
# 設置畫布和子圖大小
fig, ax = plt.subplots(figsize=(6, 10))
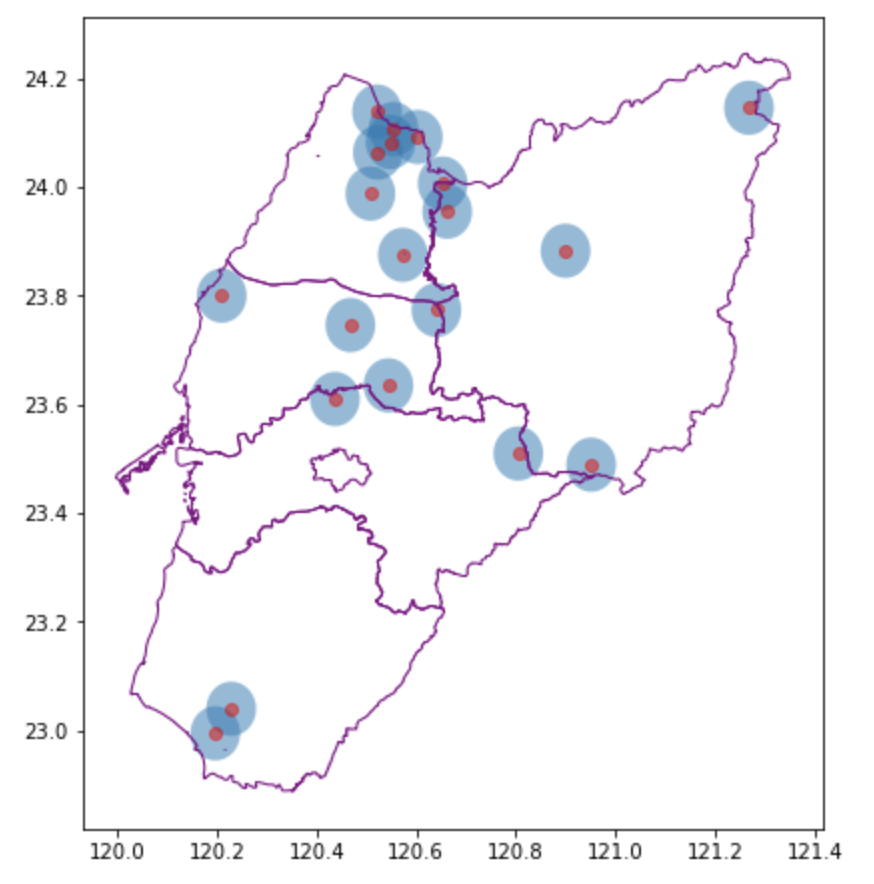
# 使用 Geopandas 的 buffer 函式建立緩衝帶,這邊緩衝帶的寬度設為 0.05
buffer = intersected_data.buffer(0.05)
# 繪製緩衝帶,透明度設為 0.5
buffer.plot(ax=ax, alpha=0.5)
# 繪製過濾後的氣象站位置,顏色設為紅色,透明度為 0.5
intersected_data.plot(ax=ax, color='red', alpha=0.5)
# 繪製嘉義縣和嘉義市的邊界
basemap.plot(ax=ax, facecolor='none', edgecolor='purple');
# 調整畫布的排版
plt.tight_layout();
多重緩衝區 (Multi-ring buffer)
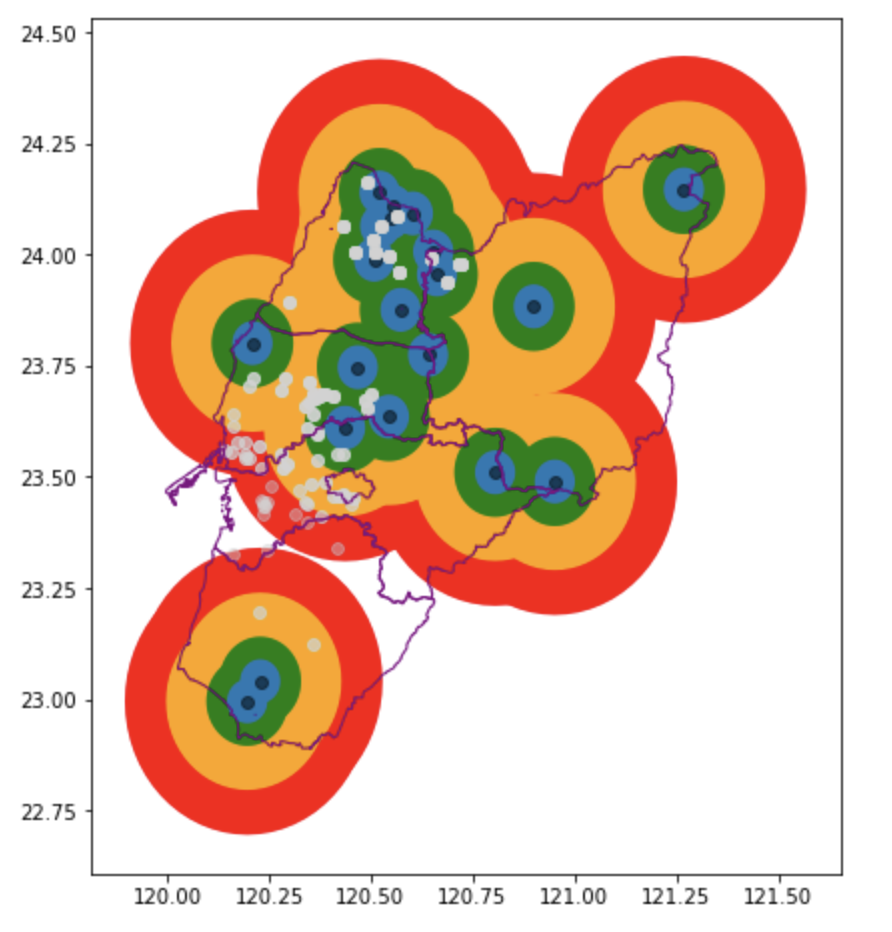
當然,我們也可以設定不同的距離半徑 ,進而把緩衝區畫成多個同心圓 (圖2),這樣就可以利用不同的遠近/階層,以將鄰近的測站分組,從而檢視越鄰近的測站是否有越相近的數值趨勢。在這個案例中,我們可以用氣象局的局屬氣象站去建立多重緩衝區,並檢視不同的緩衝區內的水利署淹水感測器,從而探勘:雨量、水平距離與淹水高度之間的關係。
# 利用不同的經緯度作為半徑以建立多重緩衝區,並依照 0.05度=藍色;0.1度=綠色;0.2度=橘色;0.3=紅色 進行顏色設定
# 設置畫布和子圖大小
fig, ax = plt.subplots(figsize=(6, 10))
# 建立不同寬度的緩衝帶,並分別以不同顏色繪製
buffer_03 = intersected_data.buffer(0.3)
buffer_03.plot(ax=ax, color='red', alpha=1)
buffer_02 = intersected_data.buffer(0.2)
buffer_02.plot(ax=ax, color='orange', alpha=1)
buffer_01 = intersected_data.buffer(0.1)
buffer_01.plot(ax=ax, color='green', alpha=1)
buffer_005 = intersected_data.buffer(0.05)
buffer_005.plot(ax=ax, alpha=1)
# 繪製原始交集點,用黑色表示
intersected_data.plot(ax=ax, color='black', alpha=0.5)
# 建立最大緩衝帶(0.3)的 GeoDataFrame,然後和淹水感測器進行空間交集運算
buffer = gpd.GeoDataFrame(buffer_03, geometry=buffer_03)
buffer = buffer.to_crs(4326)
intersected_flood = gpd.overlay(gdf_flood, buffer, how='intersection')
# 繪製交集後的淹水感測器位置,用淺灰色表示
intersected_flood.plot(ax=ax, color='lightgray', alpha=0.5)
# 繪製嘉義縣和嘉義市的邊界
basemap.plot(ax=ax, facecolor='none', edgecolor='purple');
# 調整畫布的排版
plt.tight_layout();
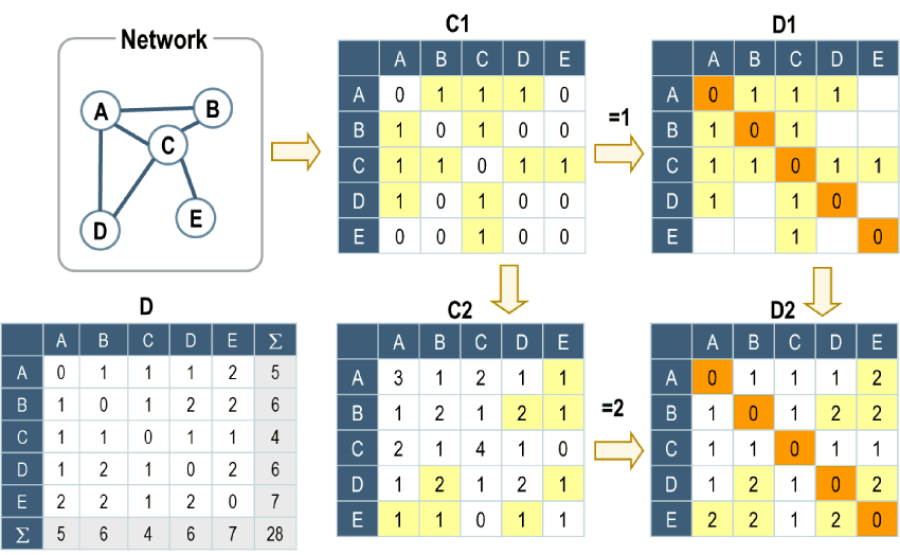
距離矩陣 (Distance Matrix)
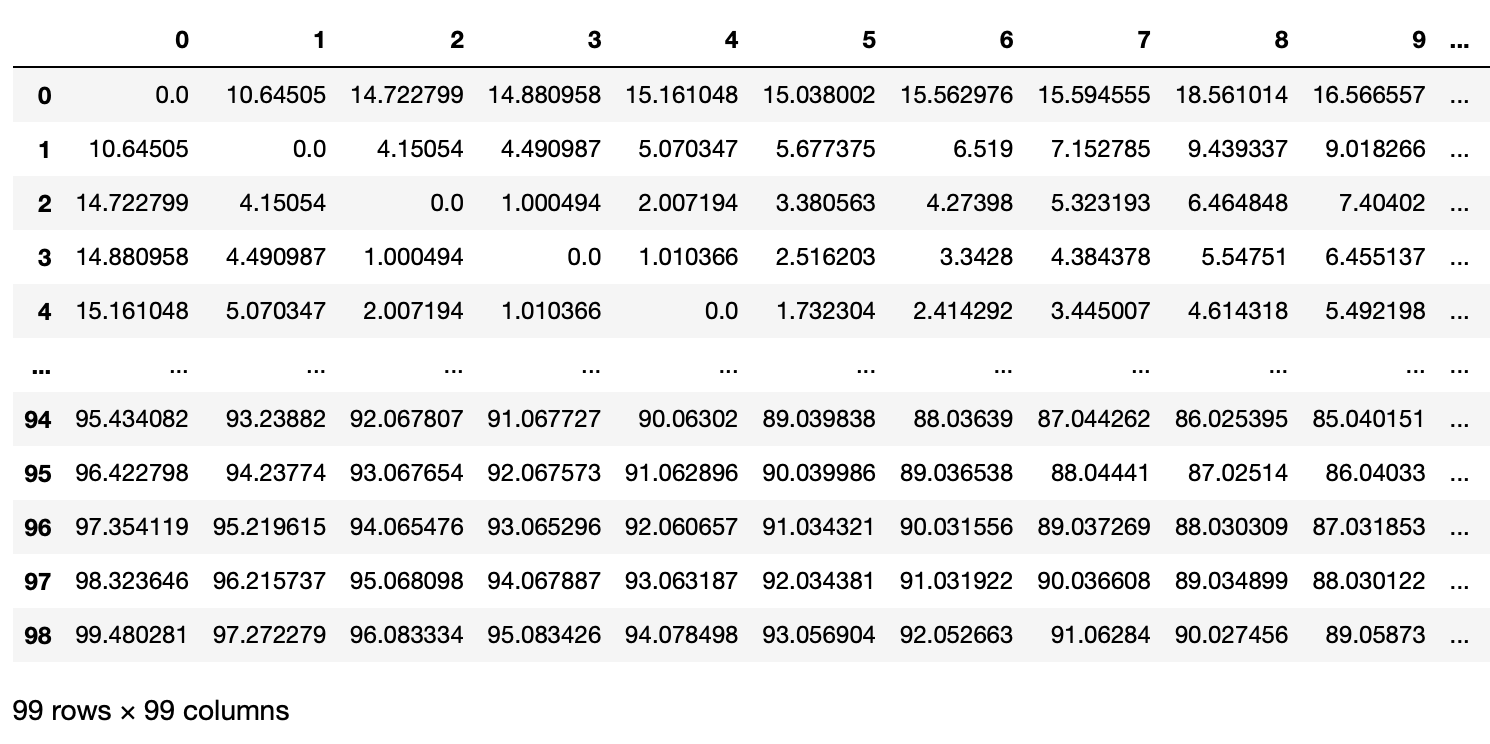
最後,因為每一個測站都有具體的座標數值,所以我們也可以三角函式結合座標數值,取得兩兩測站間的絕對距離,從而建立所有測站間的距離矩陣 (distance matrix),而這樣的矩陣可以協助我們快速檢視兩兩測站間的距離關係,並從中確認測站是否具有鄰近性,從而以更一步確認感測間的數值趨勢是否與其距離具有相關性 (圖3)。在這個範例中,我們可以利用台北市內的淹水感測器位置,並將其轉換成為距離矩陣,以協助我們掌握淹水是否具有鄰近關係。
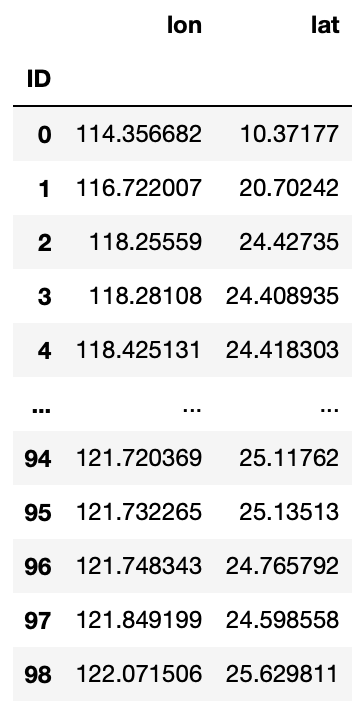
# 為了製作距離矩陣,先將 gdf_weather 資料整理一下,新增一個 'ID' 欄位來存放 index
gdf_weather["ID"] = gdf_weather.index
# 挑選出需要的欄位('ID', 'lon', 'lat'),並建立一個新的 DataFrame
df = pd.DataFrame(gdf_weather, columns=['ID','lon', 'lat'])
# 將 'ID' 設定為 DataFrame 的 index
df.set_index('ID', inplace=True)
# 引入 scipy 的 distance_matrix 函式來計算距離
from scipy.spatial import distance_matrix
# 使用 distance_matrix 函式計算 df(感測器的經緯度)彼此之間的距離
# 輸出會是一個距離矩陣,然後再轉成 DataFrame 格式
distance_df = pd.DataFrame(distance_matrix(df.values, df.values), index=df.index, columns=df.index)
小結
透過前述的方式,我們可以從地理空間 (行政區或鄰近性) 進行測站的篩選機制,並從而能從地理空間的特性檢視測站間的數值相關性。
References
- Geopanda Documentation (https://geopandas.org/en/stable/docs.html)
- Shpfile 格式介紹 (https://en.wikipedia.org/wiki/Shapefile)
- 臺灣的大地基準及座標系統 (https://wiki.osgeo.org/wiki/Taiwan_datums)
- WGS 84 (EPSG:4326) 參數介紹 (https://epsg.io/4326)
- TWD 97 (EPSG:3826) 參數介紹 (https://epsg.io/3826)
