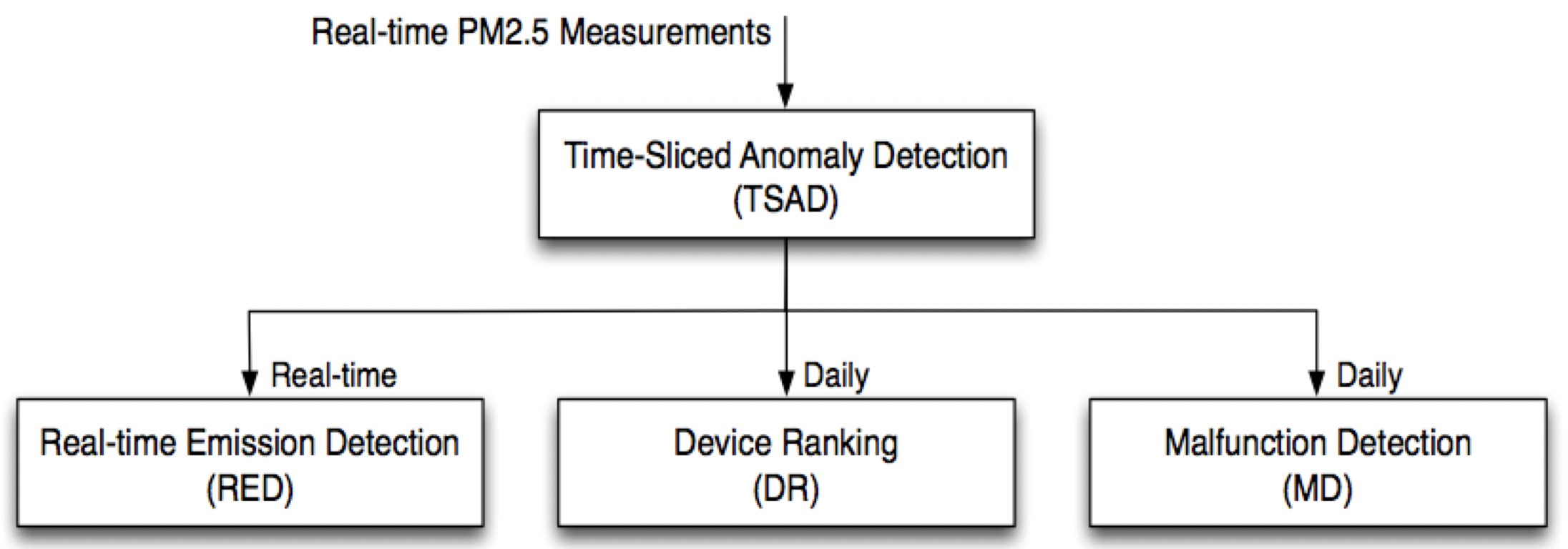
6.2. 異常資料偵測
![]()
Table Of Contents
異常檢測框架
目前已有多個大規模微型空品監測系統成功部署於不同的國家與城市之中,然而這些微型感測器的主要挑戰之一為如何確保數據品質,並且能即時偵測出可能的異常現象。在台灣的中央研究院資訊科學研究所網路實驗室研究團隊,於2018年提出了一種可用於實際環境中的異常檢測框架,稱之為 Anomaly Detection Framework (ADF)。
此異常檢測框架由四個模組所組成:
- 時間片斷異常偵測 (Time-Sliced Anomaly Detection, TSAD):可即時偵測感測器於空間或時間上的異常數據,並將結果輸出給其他模組進行進一步分析。
- 即時污染偵測模組 (Real-time Emission Detection, RED):可透過 TSAD 的偵測結果,即時檢測潛在的區域性污染事件。
- 感測器可靠度評估模組 (Device Ranking, DR):可累積 TSAD 的偵測結果,並據以評估每個微型感測器設備的可靠度
- 非正常使用機器偵測模組 (Malfunction Detection, MD):可累積 TSAD 的偵測結果,透過數據分析判別可能為非正常使用的微型感測器,例如安裝在室內的機器、安置在持續性污染源旁邊的機器等。
異常事件種類
在 ADF 框架中,TSAD 模組在微型感測器每次收到新的感測資料後,便會進行時間類或空間類的異常事件判斷,我們以微型空品感測器為例,進行說明:
- 時間類異常事件:我們假設空氣的擴散是均勻緩慢的,因此同一台微型空品感測器在短時間內的數值變化應極為平緩,如果有某台微型空品感測器的感測數值在短時間內出現劇烈的變化,代表在時間維度上可能出現異常事件。
- 空間類異常事件:我們可以假設戶外的空氣在地理空間上是會均勻擴散的,因此微型空品感測器的感測數值,理應與周圍鄰近的感測器相似,如果有某台微型空品感測器的感測數值,與同時間鄰近區域的微型空品感測器的感測數值出現極大的差異,代表該感測器所處的空間可能出現異常事件。
異常事件可能原因
以上所述的異常事件有許多可能的原因,常見的原因有:
- 安裝環境異常:感測器被安裝於特定環境,因此無法呈現整體環境現象,例如安裝於廟宇旁、燒烤店內或其他室內不通風的地點。
- 機器故障或安裝錯誤:例如感測器安裝時將取風口的方向弄錯,或者感測器的風扇積垢導致運轉不順暢。
- 出現臨時污染源:例如感測器旁邊剛好有人在抽菸、發生火災或排放污染物質。
實際案例演練
在這篇文章中,我們將以民生公共物聯網中的空品資料為例,使用部分佈建於高雄市的校園微型空品感測器來進行分析,並且介紹如何使用 ADF 檢測框架來找出其中可能為室內機器或位於污染源附近的機器,藉此過濾出可信度相對較低的機器們,進而提高整體空品感測結果的可信度。
套件安裝與引用
在這個案例中,我們將會使用到 pandas, numpy, plotly 和 geopy 等套件,這些套件在我們使用的開發平台 Google Colab 上已有預先提供,因此我們不需要另行安裝,可以直接用下列的方法引用,以備之後資料處理與分析使用。
# 引入 pandas 與 numpy 模組,用於資料分析和處理。
import pandas as pd
import numpy as np
# 引入 plotly.express 模組,用於資料視覺化。
import plotly.express as px
# 引入 geopy.distance 中的 geodesic 模組,用於計算兩地點之間的距離。
from geopy.distance import geodesic
讀取資料與環境設定
在這個案例中,我們將使用部分民生公共物聯網佈建於高雄的校園微型空品感測器來進行分析,我們所設定的時間和空間範圍如下:
- 地理區域:緯度:
22.631231 - 22.584989, 經度:120.263422 - 120.346764 - 時間區間:2022.10.15 - 2022.10.28
註:校園微型空品感測器的原始資料請至 民生公共物聯網-資料服務平台下載,為了方便讀者可以重現這個範例的內容和結果,我們先把所有使用到的資料整理成 allLoc.csv 檔案,做為接下來資料分析的依據。
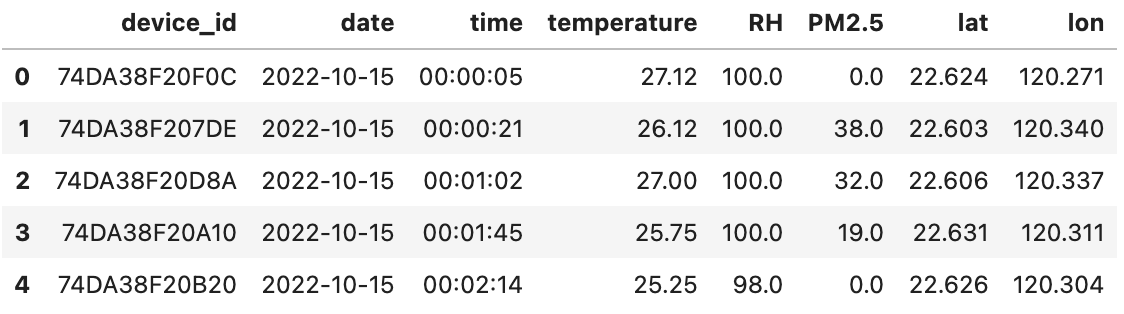
我們首先載入資料檔案,並預覽資料的內容:
# 使用 pandas 的 read_csv 方法從指定的 URL 讀取 CSV 檔案,並將其存入 DF 這個 DataFrame 中。
DF = pd.read_csv("https://LearnCIOT.github.io/data/allLoc.csv")
# 呼叫 DataFrame 的 head 方法,預設顯示前五筆資料以檢查其內容。
DF.head()
接著我們擷取資料檔中每個感測器的 GPS 地理位置座標,由於這些感測器的 GPS 座標都不會改變,我們使用比較特別的方式,將資料檔中每個感測器的經度和緯度資料各自取平均值,做為該感測器的地理位置座標。
# 從 DF 中選取 "device_id", "lon", "lat" 這三列,然後按照 "device_id" 進行分組,計算平均值,再重設索引。
dfId = DF[["device_id","lon","lat"]].groupby("device_id").mean().reset_index()
# 輸出 dfId 的前五筆資料以檢查其內容。
print(dfId.head())
device_id lon lat
0 74DA38F207DE 120.340 22.603
1 74DA38F20A10 120.311 22.631
2 74DA38F20B20 120.304 22.626
3 74DA38F20B80 120.350 22.599
4 74DA38F20BB6 120.324 22.600
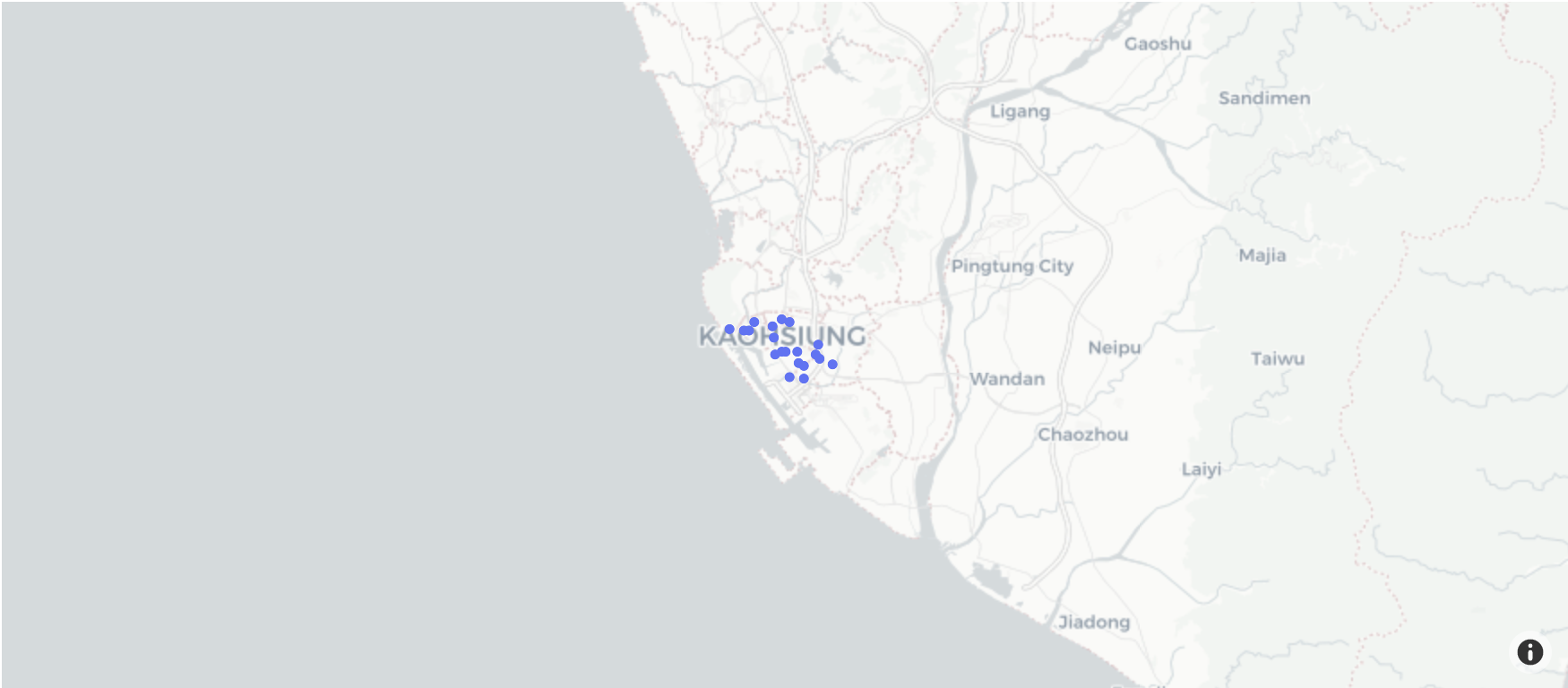
為了大致了解資料檔內感測器的地理位置分布,我們將感測器的位置繪製在地圖上。
# 使用 plotly.express 的 scatter_mapbox 函數,根據 dfId 的經緯度數據繪製散點地圖。
# 設定連續色階為 IceFire,初始放大級別為 9,並使用 "carto-positron" 的地圖風格。
fig_map = px.scatter_mapbox(dfId, lat="lat", lon="lon",
color_continuous_scale=px.colors.cyclical.IceFire, zoom=9,
mapbox_style="carto-positron")
# 顯示地圖視覺化結果。
fig_map.show()
尋找鄰近的感測器
由於我們所使用的校園微型空氣品質感測器都是固定安裝在校園內,其 GPS 地理位置座標並不會改變,為了節省之後資料分析的運算時間,我們先統一將每個感測器的「鄰居」清單計算出來。在我們的案例中,我們定義如果兩個微型感測器的相互距離小於等於 3 公里,那麼這兩個感測器變互為鄰居關係。
我們首先撰寫一個小函式 countDis,可以針對輸入的兩個 GPS 地理座標位置,計算兩者之間的實體公里距離。
# 定義一個 countDis 函式,用於計算兩個裝置間的地理距離。
# 輸入為兩個裝置的資訊(含經緯度),輸出為兩裝置間的距離(公里)。
def countDis(deviceA, deviceB):
return geodesic((deviceA["lat"], deviceB['lon']), (deviceB["lat"], deviceB['lon'])).km
接著我們將原有資料的感測器列表從 DataFrame 資料型態,轉化成 Dictionary 資料型態,並且計算所有任意兩個感測器間的距離,只要兩者間的距離小於 3km,便將彼此存入對方的鄰居感測器列表 dicNeighbor 中。
# 設定兩個鄰近裝置間的最大距離為 3 公里。
DISTENCE = 3
# 將 DataFrame 轉換成字典格式。
# 格式為:{iD: {'lon': 經度值, 'lat': 緯度值}, ...}。
dictId = dfId.set_index("device_id").to_dict("index")
# 取得感測器 device_id 的列表。
listId = dfId["device_id"].to_list()
# 初始化 dicNeighbor 字典。
# 格式為:{iD: []}。
dicNeighbor = {iD: [] for iD in listId}
# 使用 countDis 函數計算每兩個感測器之間的距離。
# 如果兩感測器間的距離小於 3 公里,則認定它們為彼此的鄰居。
# 時間複雜度:N!
for x in range(len(listId)):
for y in range(x+1, len(listId)):
if ( countDis( dictId[listId[x]], dictId[listId[y]]) < DISTENCE ):
dicNeighbor[listId[x]].append( listId[y] )
dicNeighbor[listId[y]].append( listId[x] )
每五分鐘進行感測資料的時間切片
由於原始資料中每個感測器的感測資料在時間上並未同步,在 ADF 框架中提出將感測資料以每單位時間為間隔,獲取整體感測結果的時間切片 (time slice)。我們首先將原始資料中的 date 和 time 兩個欄位進行整併,並以 Python 語言中的 datetime 時間資料型態,儲存形成 datetime 新欄位,接著再將原有的 date、time、RH、temperature、lat、lon 等不需要的欄位刪除。
# 將 'date' 和 'time' 這兩列結合,創建一個新的列 'datetime'。
DF["datetime"] = DF["date"] + " " + DF["time"]
# 移除一些不必要的列。
DF.drop(columns=["date","time", "RH","temperature","lat","lon"], inplace=True)
# 將新的 'datetime' 列轉換為 datetime 資料型態。
DF['datetime'] = pd.to_datetime(DF.datetime)
由於我們所處理的校園微型空氣品質感測器的資料頻率約為 5 分鐘,因此我們將時間切片的單位時間 FREQ 也設為 5 分鐘,並計算每五分鐘內,每個感測器所回傳的感測值的平均值。為了確保資料正確性,我們也多做了一道檢查,將 PM2.5 感測值為負數的資料予以刪除。
# 設定分組的頻率為 '5min'。
FREQ = '5min'
# 根據 'device_id' 和頻率為 '5min' 的 'datetime' 進行分組,然後計算每組的平均值。
dfMean = DF.groupby(['device_id', pd.Grouper(key = 'datetime', freq = FREQ)]).agg('mean')
# 移除無效紀錄,即 PM2.5 小於 0 的資料。
dfMean = dfMean[ dfMean['PM2.5'] >= 0 ]
# 輸出 dfMean 的前五筆資料以檢查。
print(dfMean.head())
PM2.5
device_id datetime
74DA38F207DE 2022-10-15 00:00:00 38.0
2022-10-15 00:05:00 37.0
2022-10-15 00:10:00 37.0
2022-10-15 00:20:00 36.0
2022-10-15 00:25:00 36.0
以時間切片為單位計算鄰居感測器的平均感測值
為了計算在特定時間切片上,特定感測器的鄰居感測器的平均感測值,我們撰寫 cal_mean 函式,可以根據輸入的特定感測器代碼 iD 與時間戳記 dt,回傳該感測器的鄰居感測器數量與平均感測值。
# 定義一個函數 cal_mean,用於計算某個裝置在某個時間點的鄰居裝置的 PM2.5 平均值。
def cal_mean(iD, dt):
# 從 dfMean 中選取符合指定時間 dt 和指定裝置 iD 的鄰居裝置的 PM2.5 資料。
neighborPM25 = dfMean[
(dfMean.index.get_level_values('datetime') == dt)
& (dfMean.index.get_level_values(0).isin(dicNeighbor[iD]))
]["PM2.5"]
# 計算鄰居裝置的 PM2.5 平均值。
avg = neighborPM25.mean()
# 計算有多少鄰居裝置的 PM2.5 資料被考慮。
neighbor_num = neighborPM25.count()
# 回傳平均值和鄰居裝置的數量。
return avg, neighbor_num
接著我們針對 dfMean 中每台感測器的每個時間戳記,計算其鄰居感測器的數量與平均感測值,並分別存入 avg 與 neighbor_num 兩個新欄位中。比較特別的是,這邊我們使用 zip 和 apply 的語法,可以將 DataFrame 的數值帶入函式當中進行運算,其中:
- 我們使用
zip的語法,用於打包apply_func所回傳的兩個參數值。 - 我們使用
apply的語法,以配合 DataFrame 的規則,接收apply_func的回傳值。
# 定義一個函數 apply_func,將 cal_mean 函式適用於 dfMean 的每一列。
# 使用 x.name 取得當前列的索引值 (裝置ID 和時間),並傳遞給 cal_mean 函式。
def apply_func(x):
return cal_mean(x.name[0], x.name[1])
# 使用 apply 函式和 apply_func,計算 dfMean 中每一列的 PM2.5 平均值和鄰居裝置的數量。
# 結果會被分解並分別存儲在 'avg' 和 'neighbor_num' 這兩列。
dfMean['avg'], dfMean['neighbor_num'] = zip(*dfMean.apply(apply_func, axis=1))
# 輸出 dfMean 的前五筆資料以檢查。
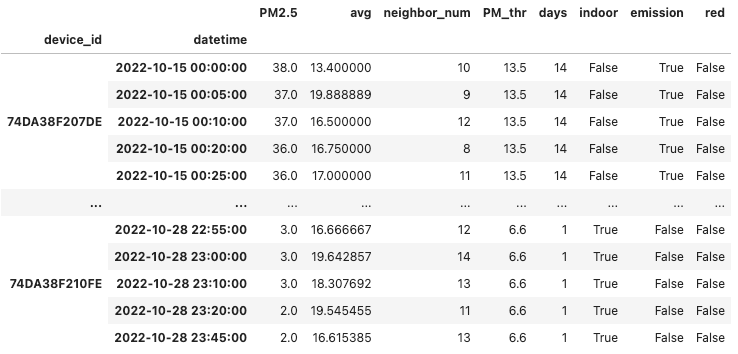
print(dfMean.head())
PM2.5 avg neighbor_num
device_id datetime
74DA38F207DE 2022-10-15 00:00:00 38.0 13.400000 10
2022-10-15 00:05:00 37.0 19.888889 9
2022-10-15 00:10:00 37.0 16.500000 12
2022-10-15 00:20:00 36.0 16.750000 8
2022-10-15 00:25:00 36.0 17.000000 11
判斷異常事件的門檻值
我們透過觀察發現,所謂的「異常事件」指的是感測器的感測值,與我們心中認定的合理值有過大的差距,這個合理值有可能是鄰近的感測器感測值(空間類異常),也有可能是同一個感測器的前一筆感測值(時間類異常),或者是根據其他資訊來源的合理推估值。同時,我們也發現所謂的「過大的差距」,其實是一個很模糊的說法,其具體數值隨感測值的大小,亦有極大的不同。
因此,我們首先根據現有 dfMean[’avg'] 的分布狀況,切分為 9 個區間,並且針對每一個區間的 PM2.5 感測值,計算其標準差,並據以做為判斷感測值是否異常的門檻值標準,如下表所示。舉例來說,當原始數值為 10 (ug/m3) 時,倘若周圍感測器平均高於 10+6.6 ,或低於 10-6.6 ,我們便會認定該感測器的該筆感測值為異常事件。
| 原始數值 (ug/m3) | 門檻值標準 |
|---|---|
| 0-11 | 6.6 |
| 12-23 | 6.6 |
| 24-35 | 9.35 |
| 36-41 | 13.5 |
| 42-47 | 17.0 |
| 48-58 | 23.0 |
| 59-64 | 27.5 |
| 65-70 | 33.5 |
| 71+ | 91.5 |
根據這個對照表,我們撰寫下列的函式 THRESHOLD,根據輸入的感測數值,回傳對應的門檻值,並將此門檻值存入 dfMEAN 的新欄位 PM_thr 中。
# 定義一個函數 THRESHOLD,根據 PM2.5 的值傳回相應的閾值。
def THRESHOLD(value):
if value<12:
return 6.6
elif value<24:
return 6.6
elif value<36:
return 9.35
elif value<42:
return 13.5
elif value<48:
return 17.0
elif value<54:
return 23.0
elif value<59:
return 27.5
elif value<65:
return 33.5
elif value<71:
return 40.5
else:
return 91.5
# 使用 apply 方法和 THRESHOLD 函式,計算 dfMean 中每一列 PM2.5 的閾值。
# 結果存入新的 'PM_thr' 列中。
dfMean['PM_thr'] = dfMean['PM2.5'].apply(THRESHOLD)
由於原始資料的最後一筆紀錄的時間是 2022-10-28 23:45,因此我們將資料判斷的時間設為 2022-10-29 日,並將原始資料中每一筆紀錄與資料判斷時間的差距,存入 dfMEAN 的新欄位 days 中。接著我們先預覽一下目前 dfMEAN 資料表的狀況。
# 設定目標日期為 "2022-10-29"。
TARGET_DATE = "2022-10-29"
# 使用 assign 方法,計算 dfMean 中每一列時間與目標日期的天數差距。
# 結果存入在新的 'days' 列中。
dfMean = dfMean.assign(days = lambda x: ( (pd.to_datetime(TARGET_DATE + " 23:59:59") - x.index.get_level_values('datetime')).days ) )
# 輸出 dfMean 的前五筆資料以檢查。
print(dfMean.head())
PM2.5 avg neighbor_num PM_thr days
device_id datetime
74DA38F207DE 2022-10-15 00:00:00 38.0 13.400000 10 13.5 14
2022-10-15 00:05:00 37.0 19.888889 9 13.5 14
2022-10-15 00:10:00 37.0 16.500000 12 13.5 14
2022-10-15 00:20:00 36.0 16.750000 8 13.5 14
2022-10-15 00:25:00 36.0 17.000000 11 13.5 14
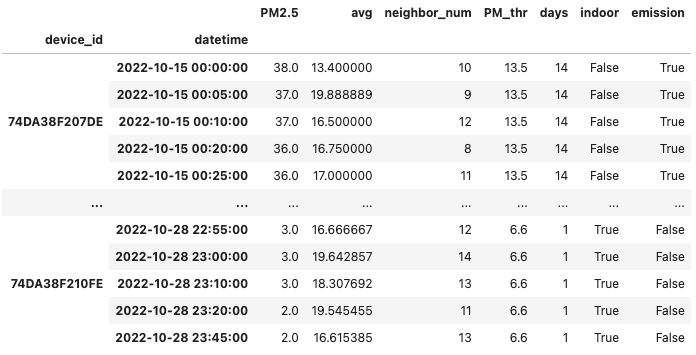
非正常使用機器偵測模組 (MD) 實作
在接下來的範例中,我們實作 ADF 中的非正常使用機器偵測模組 (Malfunction Detection, MD),其核心觀念為,倘若我們將某一個微型感測器的 PM2.5 數值與其周圍 3 公里內的其他感測器進行比較,如果其感測數值低於鄰近感測器的平均值 (avg) 減掉可接受的門檻值 (PM_thr),則將該機器視為裝設在室內的機器(標記為indoor);如果其感測數值高於鄰近感測器的平均值 (avg) 加上可接受的門檻值 (PM_thr),則將該機器視為裝設在污染源旁的機器(標記為emission)。為了避免因為參考的鄰近感測器數量不夠導致誤判,我們只採計鄰近區域存有多於 2 個其他感測器的案例。
# 設定最小鄰居數量為 2。
MINIMUM_NEIGHBORS = 2
# 計算 "indoor" 標籤。
# 如果當前裝置的 PM2.5 平均值與該裝置的 PM2.5 值的差大於閾值,且該裝置的鄰居數量大於或等於最小鄰居數量,則為 True,否則為 False。
dfMean["indoor"] = ((dfMean['avg'] - dfMean['PM2.5']) > dfMean['PM_thr']) & (dfMean['neighbor_num'] >= MINIMUM_NEIGHBORS)
# 計算 "emission" 標籤。
# 如果該裝置的 PM2.5 值與 PM2.5 平均值的差大於閾值,且該裝置的鄰居數量大於或等於最小鄰居數量,則為 True,否則為 False。
dfMean["emission"] = ((dfMean['PM2.5'] - dfMean['avg']) > dfMean['PM_thr']) & (dfMean['neighbor_num'] >= MINIMUM_NEIGHBORS)
# 顯示 dfMean 的內容。
dfMean
由於每日的空氣品質狀況不同,對於 indoor 和 emission 的判斷結果也會產生不同程度的影響,為了獲得更有說服力的判斷結果,我們考慮過去 1 天、7 天、 14 天等三個時間長度,分別計算在不同時間長度下,同一個感測器被判斷為 indoor 或 emission 的比例。同時,為了避免外在環境導致的誤判影響最後的判斷結果,我們強制修改計算出來的結果,將比例小於 1/3 的數值,強制改為 0。
# 初始化兩個字典,用於儲存每個裝置的 "indoor" 和 "emission" 的紀錄。
dictIndoor = {iD: [] for iD in listId}
dictEmission = {iD: [] for iD in listId}
# 迴圈遍歷每一個裝置 iD 進行計算。
for iD in listId:
# 選取與當前裝置 iD 相符的資料。
dfId = dfMean.loc[iD]
# 對於 [1, 7, 14] 這三個天數,計算其 "indoor" 和 "emission" 的比例。
for day in [1, 7, 14]:
# 計算 "indoor" 的比例,並四捨五入到小數點後三位。
indoor = (dfId[ dfId['days'] <= day]['indoor'].sum() / len(dfId[ dfId['days'] <= day])).round(3)
# 若 "indoor" 的比例大於 0.333,則記錄該裝置的 iD 值,否則記錄 0。
dictIndoor[iD].append(
indoor if indoor > 0.333 else 0
)
# 計算 "emission" 的比例,並四捨五入到小數點後三位。
emission = (dfId[ dfId['days'] <= day]['emission'].sum() / len(dfId[ dfId['days'] <= day])).round(3)
# 若 "emission" 的比例大於 0.333,則記錄該裝置的 iD 值,否則記錄 0。
dictEmission[iD].append(
emission if emission > 0.333 else 0
)
我們接著分別輸出 dictIndoor 和 dictEmission 的內容,觀察判斷出來的結果。
# 輸出 dictIndoor 的內容。
dictIndoor
{'74DA38F207DE': [0, 0, 0],
'74DA38F20A10': [0, 0, 0],
'74DA38F20B20': [0.995, 0.86, 0.816],
'74DA38F20B80': [0.995, 0.872, 0.867],
'74DA38F20BB6': [0, 0, 0],
'74DA38F20C16': [0.989, 0.535, 0],
'74DA38F20D7C': [0, 0, 0],
'74DA38F20D8A': [0, 0, 0],
'74DA38F20DCE': [0, 0, 0],
'74DA38F20DD0': [0.984, 0.871, 0.865],
'74DA38F20DD8': [0, 0.368, 0.369],
'74DA38F20DDC': [0, 0, 0],
'74DA38F20DE0': [0, 0, 0],
'74DA38F20DE2': [0, 0, 0],
'74DA38F20E0E': [0, 0, 0],
'74DA38F20E42': [0.99, 0.866, 0.87],
'74DA38F20E44': [0, 0, 0],
'74DA38F20F0C': [0.979, 0.872, 0.876],
'74DA38F20F2C': [0, 0, 0],
'74DA38F210FE': [0.99, 0.847, 0.864]}
# 輸出 dictEmission 的內容。
dictEmission
{'74DA38F207DE': [0.92, 0.737, 0.735],
'74DA38F20A10': [0, 0, 0],
'74DA38F20B20': [0, 0, 0],
'74DA38F20B80': [0, 0, 0],
'74DA38F20BB6': [0.492, 0.339, 0],
'74DA38F20C16': [0, 0, 0],
'74DA38F20D7C': [0.553, 0.342, 0.337],
'74DA38F20D8A': [0.672, 0.457, 0.388],
'74DA38F20DCE': [0.786, 0.556, 0.516],
'74DA38F20DD0': [0, 0, 0],
'74DA38F20DD8': [0, 0, 0],
'74DA38F20DDC': [0.345, 0, 0],
'74DA38F20DE0': [0.601, 0.503, 0.492],
'74DA38F20DE2': [0, 0, 0],
'74DA38F20E0E': [0.938, 0.75, 0.75],
'74DA38F20E42': [0, 0, 0],
'74DA38F20E44': [0.938, 0.69, 0.6],
'74DA38F20F0C': [0, 0, 0],
'74DA38F20F2C': [0.744, 0.575, 0.544],
'74DA38F210FE': [0, 0, 0]}
由上述的結果可以發現,對於 indoor 和 emission 的判斷結果,隨著參考的過往時間長短,存在不小的差異,由於不同過往時間的長度代表不同的參考意義,因此我們使用權重的方式,給予 1 天參考時間的權重為 A ,給予 7 天參考時間的權重為 B ,最後給予 14 天參考時間的權重為 1-A-B 。
同時,我們考量在一天參考時間內的工作時間約為 24 小時中的 8 小時,七天參考時間內的工作時間約為 168 小時中的 40 小時,14 天參考時間內的工作時間約為 336 小時中的 80 小時,因此若一個感測器被判斷為 indoor 或 emission 類型,其在 MD 中所佔的加權比重應大於等於 MD_thresh,且
MD_thresh = (8.0/24.0)*A+(40.0/168.0)B+(80.0/336.0)(1-A-B)
在我們的範例中,我們假定 A=0.2,B=0.3,因此我們可以透過下列的程式獲得加權判斷後的 indoor 和 emission 類別感測器清單。
# 定義常數 A 為 1 天參考時間的權重, B 表示 7 天參考時間的權重。
A=0.2
B=0.3
# 計算 MD_thresh 的值,此值將用作後續的閾值。
MD_thresh=(8.0/24.0)*A+(40.0/168.0)*B+(80.0/336.0)*(1-A-B)
# 初始化兩個列表,用於儲存超過閾值的 "indoor" 和 "emission" 的裝置ID及其比例。
listIndoorDevice = []
listEmissionDevice = []
# 迴圈遍歷每一個裝置 iD 進行計算。
for iD in listId:
# 計算 "indoor" 的加權比重。
# 如果加權比重超過 MD_thresh,則將其加入 listIndoorDevice。
rate1 = A*dictIndoor[iD][0] + B*dictIndoor[iD][1] + (1-A-B)*dictIndoor[iD][2]
if rate1 > MD_thresh:
listIndoorDevice.append( (iD, rate1) )
# 計算 "emission" 的加權比重。
# 如果加權比率超過 MD_thresh,則將其加入 listEmissionDevice。
rate2 = A*dictEmission[iD][0] + B*dictEmission[iD][1] + (1-A-B)*dictEmission[iD][2]
if rate2 > MD_thresh:
listEmissionDevice.append( (iD, rate2) )
我們接著分別輸出 listIndoorDevice 和 listEmissionDevice 的內容,觀察透過加權判斷出來的結果。
# 輸出 listIndoorDevice 的內容。
listIndoorDevice
[('74DA38F20B20', 0.865),
('74DA38F20B80', 0.8941),
('74DA38F20C16', 0.3583),
('74DA38F20DD0', 0.8906),
('74DA38F20DD8', 0.2949),
('74DA38F20E42', 0.8928),
('74DA38F20F0C', 0.8954),
('74DA38F210FE', 0.8841)]
# 輸出 listEmissionDevice 的內容。
listEmissionDevice
[('74DA38F207DE', 0.7726),
('74DA38F20D7C', 0.38170000000000004),
('74DA38F20D8A', 0.4655),
('74DA38F20DCE', 0.5820000000000001),
('74DA38F20DE0', 0.5171),
('74DA38F20E0E', 0.7876),
('74DA38F20E44', 0.6945999999999999),
('74DA38F20F2C', 0.5933)]
即時污染偵測模組 (RED) 實作
針對即時污染偵測 (Real-time Emission Detection, RED),我們假設某個微型感測器在連續的取樣中,如果最新的感測數值比前一次的感測數值多出 1/5 以上,代表其周遭環境出現劇烈的變化,極有可能是因為周遭出現空汙的排放現象。由於當感測數值較小時,1/5 的變化量其實在 PM2.5 的真實濃度變化上仍十分輕微,因此我們也排除感測數值小於 20 的狀況,以避免因為感測器本身的誤差導致即時污染偵測的誤判。
# 初始化 'red' 列,預設為 False。
dfMean['red'] = False
# 迴圈遍歷每一個裝置 iD 進行計算。
for iD in listId:
# 選取與當前裝置 iD 相符的資料。
dfId = dfMean.loc[iD]
p_index = '' # 前一筆資料的索引。
p_row = [] # 前一筆資料的內容。
# 遍歷當前裝置 iD 的每一筆資料。
for index, row in dfId.iterrows():
red = False # 初始化當前資料的 'red' 值為 False。
# 如果有前一筆資料,計算當前資料和前一筆資料的 PM2.5 差值。
if p_index:
diff = row['PM2.5'] - p_row['PM2.5']
# 若前一筆資料的 PM2.5 值大於 20 且差值大於前一筆資料的 PM2.5 值的 1/5,將 'red' 設為 True。
if p_row['PM2.5']>20 and diff>p_row['PM2.5']/5:
red = True
# 更新 dfMean 中對應的 'red' 值。
dfMean.loc[pd.IndexSlice[iD, index.strftime('%Y-%m-%d %H:%M:%S')], pd.IndexSlice['red']] = red
p_index = index # 更新前一筆資料的索引。
p_row = row # 更新前一筆資料的內容。
# 顯示 dfMean 的內容。
dfMean
感測器可靠度評估模組 (DR) 實作
最後,我們總結 RED 與 MD 兩個模組的判斷結果,進行微型感測器的可靠度評估 (Device Ranking, DR),其主要概念為:
- 如果感測器的感測資料常常被判定為時間類異常或空間類異常,代表該感測器的硬體,或者其所屬的環境可能有潛在的問題,需要進一步釐清。
- 如果感測器的感測資料較少被判定為異常,代表該感測器的感測數值與周遭感測器的數值具備很高的一致性,因此可信度高。
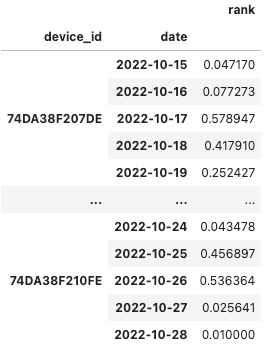
我們以日為單位,根據每個感測器每日的所有感測資料,統計曾經被判斷為時間類異常 (red=True) 或空間類異常 (indoor=True 或 emission=True) 的總次數,並計算其占一日所有資料筆數中的比例,以此做為感測器的資訊是否可靠的依據。
# 初始化一個空的 DataFrame 來存放每個裝置的排名資訊。
device_rank = pd.DataFrame()
# 迴圈遍歷每一個裝置 iD 進行計算。
for iD in listId:
# 選取與當前裝置 iD 相符的資料。
dfId = dfMean.loc[iD]
# 初始化異常計數和總數的字典。
abnormal = {}
num = {}
# 遍歷當前裝置 iD 的每一筆資料。
for index, row in dfId.iterrows():
# 初始化日期的計數值
d = index.strftime('%Y-%m-%d')
if d not in abnormal:
abnormal[d] = 0
if d not in num:
num[d] = 0
num[d] = num[d] + 1
# 檢查每一筆資料是否符合異常條件。
if row['indoor'] or row['emission'] or row['red']:
abnormal[d] = abnormal[d] + 1
# 根據異常計數和總數,計算每個裝置的排名。
for d in num:
# 將排名資訊加入 device_rank。
device_rank = device_rank.append(pd.DataFrame({'device_id': [iD], 'date': [d], 'rank': [1 - abnormal[d]/num[d]]}))
# 設定 device_rank 的索引為 'device_id' 和 'date'。
device_rank.set_index(['device_id','date'])
參考資料
- Ling-Jyh Chen, Yao-Hua Ho, Hsin-Hung Hsieh, Shih-Ting Huang, Hu-Cheng Lee, and Sachit Mahajan. ADF: an Anomaly Detection Framework for Large-scale PM2.5 Sensing Systems. IEEE Internet of Things Journal, volume 5, issue 2, pp. 559-570, April, 2018. (https://dx.doi.org/10.1109/JIOT.2017.2766085)
